Build your own Twitter
Aug 14, 2011
Twitter has been famous from two or three years ago. I had not had much idea about it till two weeks back. I really wanted to check what twitter offers and so joined twitter two weeks back. It is a nice experience exploring a new service. Whenever I do explore, I try to reverse engineer that too.
Yes, I strongly believe reverse engineering is a great way of learning things faster. To tell with an example, consider a magician who is doing some magic. Any magic is some illusion or trick, but many of us are just interested on the feeling of seeing it, not decoding it. We are just the same with the services we use too; we exploit all the services provided by Facebook, Twitter and all other social networks, but don’t care about reverse engineering and learning how that stuff works. Who knows, if you could reverse engineer Facebook, you can make a better Facebook yourself.
Now come back to twitter. When I understood what service twitter is providing, I really thought that the technique behind that is quite simple. Now, I believe that I can build a less featured Twitter (being a single man) on my own. I’ll explain what makes me believe so.
When you want to reverse engineer something, start from the data that it operates on. Most of the services that we use are about data (especially with social network). Try to build a database schema that satisfies the process that you want reverse engineer (in our case ‘Twitter’). When you finished modeling the schema, half of the reverse engineering process is finished, rest you have is to build the replica using the database that we designed. When I do it for Twitter, I ended up with just three tables (I consider only tweeting feature here for simplicity, avoided messaging service, SMS access which the real Twitter is having).
When we sign up an account, all the user details are registered, hence a user table is needed keeping the primary key as username. Signing up, in, out involves process on this table alone. I describe here about username alone as it is a must, you can add any other data related to the user on that table.
Now, Twitter has something called ‘following’ and ‘followers’ for each user (What I describe here is on an assumption that you are a user of Twitter, if not, try to become). Simply, ‘the people you follow’ and ‘the people who follow you’. How to maintain this in database? Watch closely here, ‘following’ & ‘followers’ are not two entirely different things. You are a ‘follower’ to people who have you in their ‘following’ list.
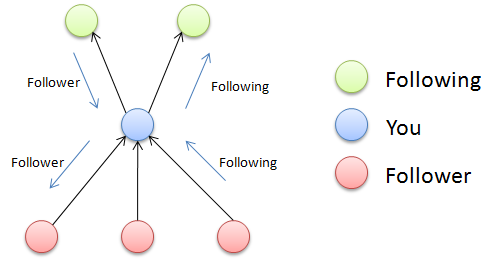
So each person has a set of followers (we don’t have to worry about following). The table contains only two fields.
| Person | Follower |
|---|---|
| User1 | User2 |
| User1 | User3 |
| User2 | User3 |
Where the User1, User2 & User3 are the usernames (primary key of first user table).
Now comes the tweets, each person tweet’s at anytime. A tweet is a message of 140 characters length.
And that’s all. All the data necessary can be now stored in our database for a simplified or less featured Twitter. Now SQL queries will fetch you anything you need. The entire database schema is as follows.
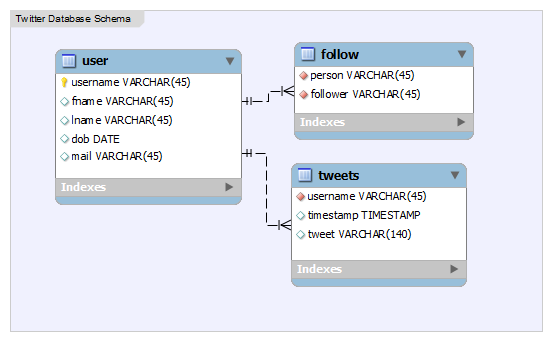
For example, home page of Twitter shows the tweets of the people you follow in time order. To accomplish this, the following query will work.
SELECT
person, timestamp, tweet
FROM tweettable
WHERE person IN (
SELECT
person
FROM follow
WHERE follower='myusername'
)
ORDER BY timestamp DESC
And you can do more. Imagine you build your own twitter for your college alone. That would be cool isn’t it? I should have done that before, but I missed it. I believe someone will build it for sure at least after reading & understanding how simple building your own twitter. Who knows, your twitter may roar rather tweeting.